01 · Problem The Challenge
Learning sign language in Indonesia is prohibitively expensive due to the high cost of private tutors. The only free alternatives are passive methods like static videos, where learners receive no feedback on whether they are signing correctly.
Humans are social creatures, and communication is a fundamental right — being disabled should not mean being disconnected from society. However, while modern Computer Vision is accurate, it typically requires high computational power that the average Indonesian, often relying on budget devices, simply does not possess.
02 · Solution The Approach
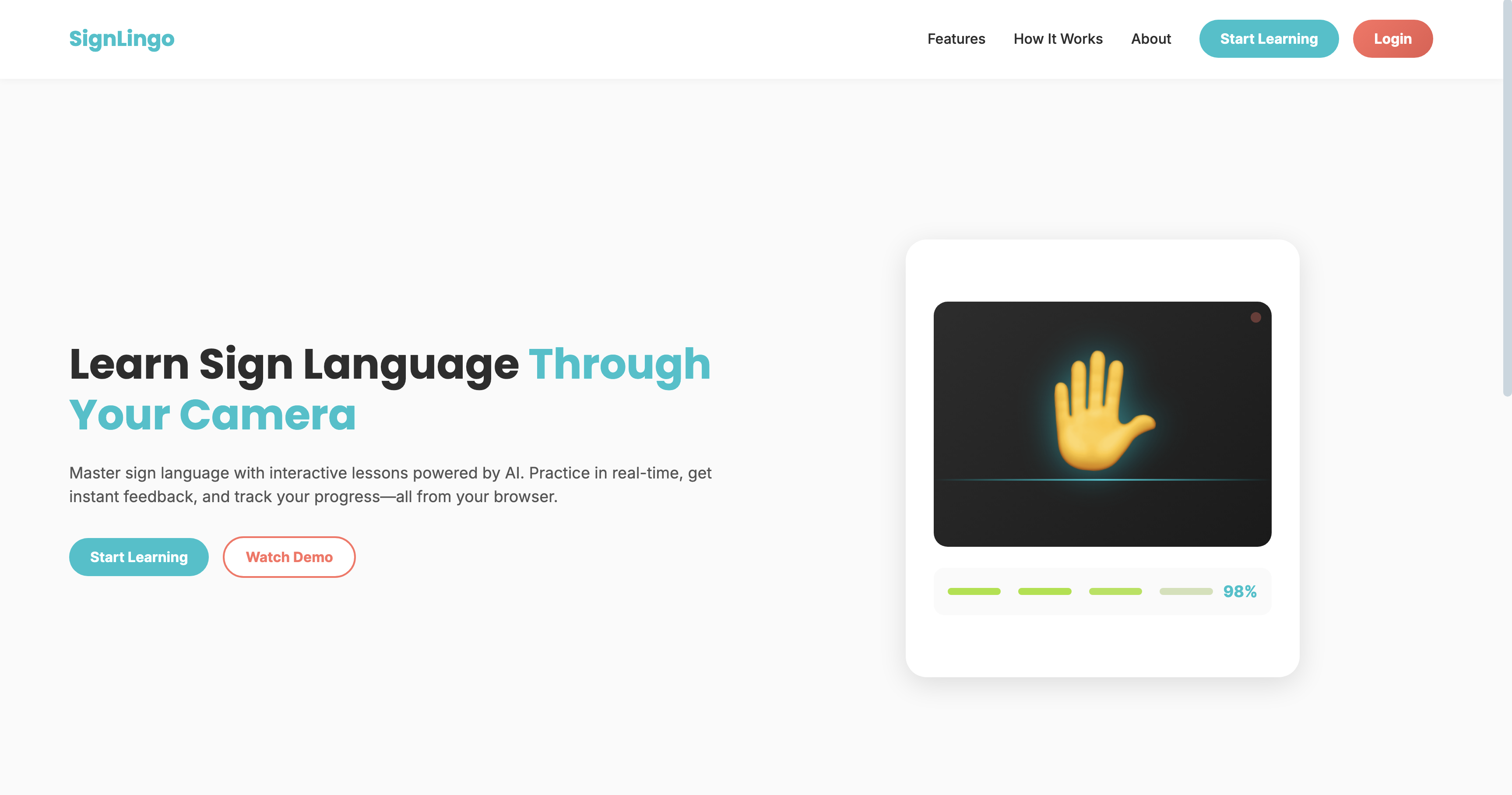
We built SignLingo to make learning accessible to everyone, everywhere. Since it is web-based, anyone can access it easily. To solve the hardware constraint, I researched and implemented a specialized lightweight Hybrid CNN-LSTM architecture. This ensures high accuracy without the need for expensive GPUs, allowing the AI to act as a personal tutor that gives instant feedback directly in the browser.
03 · Leadership My Role
SignLingo started with a simple goal: making sign language education accessible. As Product Owner, Scrum Master, Lead Developer, and Researcher, I managed a 10-person team across our business, research, and engineering tracks. While I guided our agile sprints and product strategy, my impact was heavily technical. I personally spearheaded the AI development, building the temporal feature extraction models using MediaPipe, LSTM, and GRU architectures. Alongside the machine learning, I engineered the entire backend architecture from the ground up. By bridging deep technical execution with our business roadmap, I ensured our vision translated into a robust, working application.

04 · Platform The SignLingo Ecosystem
A holistic, two-part platform designed to combine state-of-the-art AI inference with an engaging user experience — real-time detection paired with gamified learning mechanics.
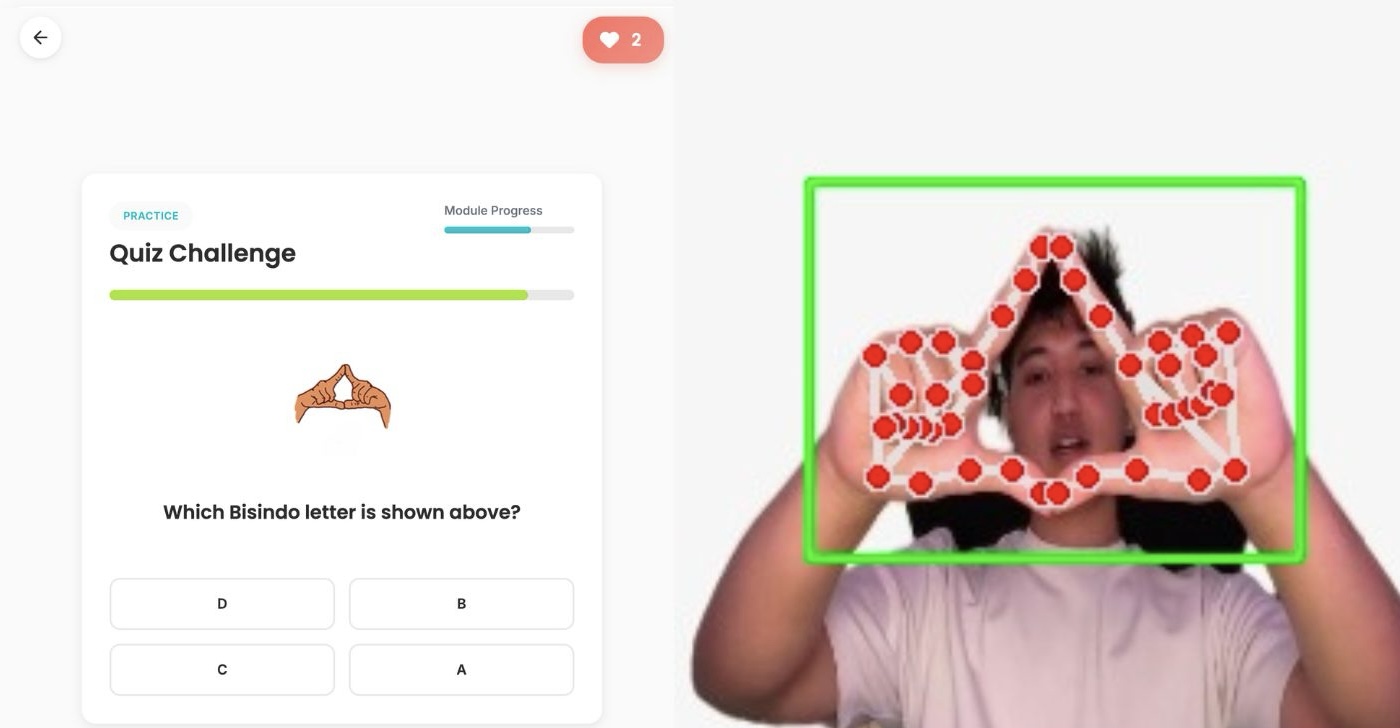
Real-time inference and active predictions
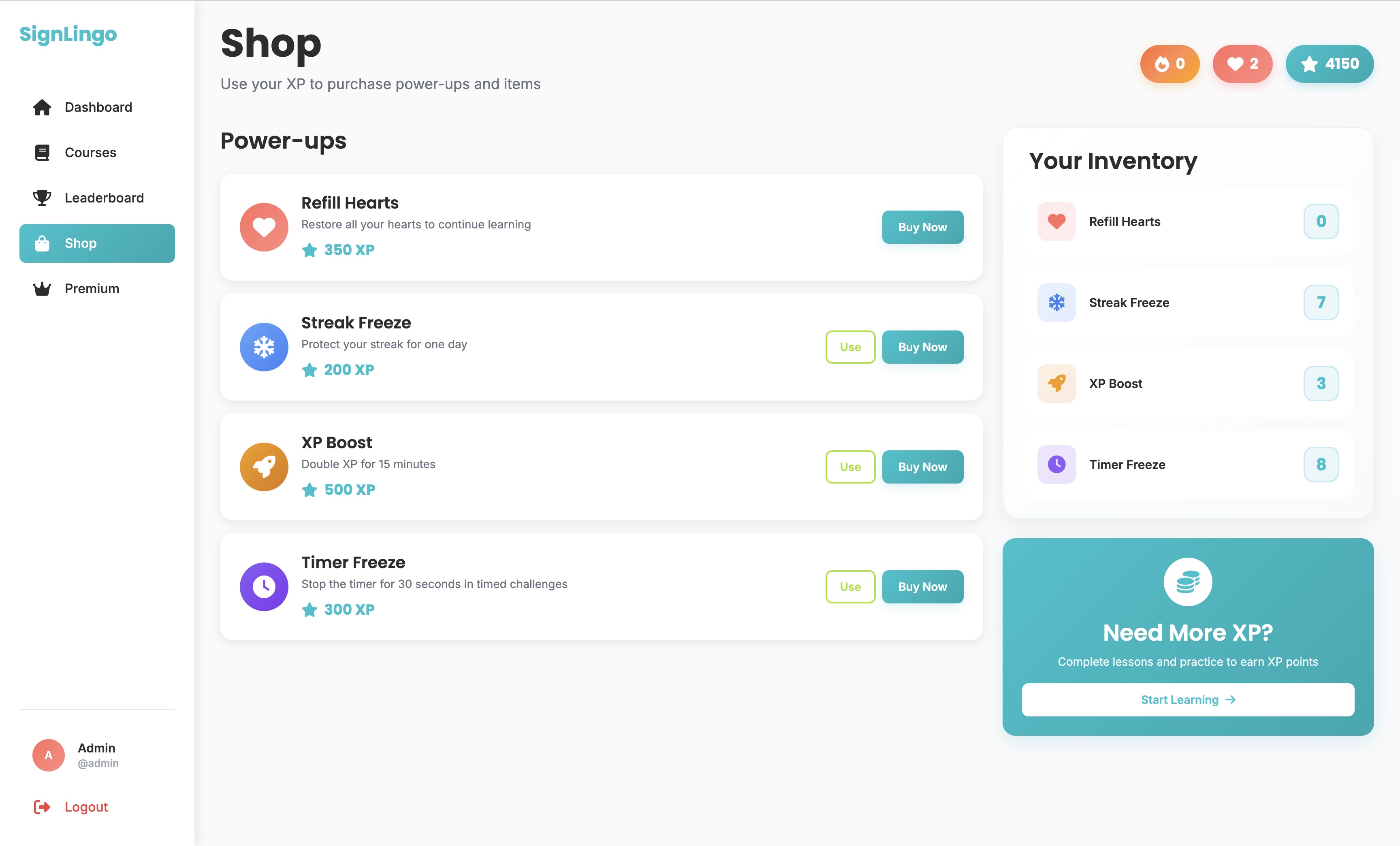
Personalized user dashboard
Real-Time Landmark Detection
Ultra-Low Latency
Inference times of 40–50ms for seamless, real-time sign language translation in the browser.
Robust Tracking
Accurate landmark detection even in low-light conditions and cluttered visual backgrounds.
Spatial-Temporal Logic
Combines spatial point coordinates extracted via MediaPipe with temporal gesture dynamics.
05 · Architecture Key Technical Architecture
To achieve high performance on constrained devices, we designed a lightweight hybrid architecture. Spatial landmarks extracted via MediaPipe are fed into a sequential CNN-LSTM network. For an in-depth dive into the methodology, data processing, and evaluation metrics, you can read the connected research paper.

Hybrid Model
MobileNetV2 for efficient spatial feature extraction combined with LSTM for temporal gesture dynamics.
Optimized for Low-Resource
L2 regularization and post-training quantization compressed the model to under 25MB — runs on 4GB RAM devices.
Gamified Learning
To move away from boring, passive learning, we designed SignLingo to be entertaining. We infused interactive "Duolingo-style" mechanics to keep users engaged while our AI acts as a private tutor giving instant feedback on their gestures.
Daily Streaks & EXP
Keep motivation high by tracking continuous learning days and rewarding experience points.
Health System
A forgiving yet challenging life system that requires active performance accuracy to progress.
Leaderboards
Compete with friends and the broader community for the top spot globally.
06 · Results The Outcome
The optimized model proved that inclusive communication technology can be made accessible to low-resource communities — without sacrificing accuracy or responsiveness.
07 · Roadmap Future Works
The journey with SignLingo doesn't stop here. Currently, I am expanding the system to support Korean Sign Language (KSL) during my exchange program at Sungkyunkwan University (SKKU). For my undergraduate thesis, I am actively upgrading the core model architecture from the current CNN-LSTM approach to a more efficient MediaPipe-GRU hybrid, aiming to further decrease latency while retaining high spatial-temporal accuracy.